-
머신러닝 - Performance Metrics (평가지표)머신러닝 & 딥러닝/머신러닝 기초 2024. 1. 24. 14:17

머신러닝 모델 평가
Bias와 Variance를 이해하면서 머신러닝의 목표는 Generalization error와 Training error를 최소화 하는 것이라고 이해했다. 그럼 머신러닝 모델을 평가하기 위해서는 어떻게 해야할까?
머신러닝은 크게 지도학습, 비지도학습, 강화학습로 구분할 수 있었다. 그 중 지도학습은 Classification, Regression으로 나눌 수 있었다. Classification 평가를 위해 여러가지 평가지표들이 있는데 이것들에 대해서 간단히 알아보자.
성능측정
머신러닝 모델 성능을 측정하기 위해 우리는 예측 값들이 결과 값들과 얼마나 근사한지 측정해야한다. Confusion Matrix를 사용해서 실제 라벨과 예측 라벨의 일치 개수를 matrix로 표현할 수 있다.

위 그림과 같이 맞음 여부와 예측 값의 조합으로 표현할 수 있다.
- True Positive(TP) : Correctly classified as the class of interest
- False Negative (FN) : Incorrectly classified as not the class of interest
- False Positive (FP) : Incorrectly classified as the class of interest
- True Negative (TN) : Correctly classified as not the class of interest
Accuracy, Sensitivity & Specificity
Accuracy란 전체 대비 정확하게 예측한 개수의 비율을 의미한다. 즉, Accuracy는 전체 테스트 데이터 개수를 정확하게 분류된 데이터 개수로 나눈것이라고 할 수 있다. Error는 1 - Accuracy가 된다.
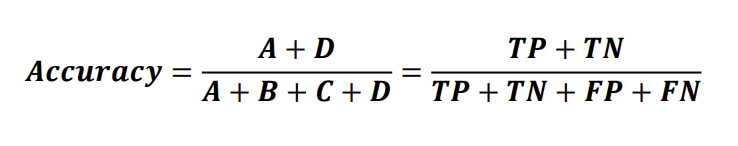
하지만 Accuracy는 Binary Classification에서 한계를 나타낸다.
Class 0의 개수를 9990, Class 1의 개수를 10이라고 가정해보자. 만약 Classifier가 모든 것이 Class 0이 된다고 예측한다면 어떻게 될까? 이 경우 Classifier가 Class 1의 예를 감지할 수 없기 때문에 왜곡이 발생한다. 즉, 정확도는 높지만 쓸모없는 모델이 만들어진다.

Sensitivity는 True Postive + False Negative를 True Positive로 나누는 것이다. 즉, True Positive의 Rate를 구하는 것이다.

Specificity는 False Positive + True Negative를 True Negative로 나누는 것이다. 즉, True Negative의 Rate를 구하는 것이다.
따라서, 우리는 Accuracy로 전체 대비 정확하게 예측한 데이터의 비율을 알 수 있다. 또한 Sensitivity로 Positive 샘플에 대한 accuracy를 구할 수 있고 Specificity로 Negative 샘플에 대한 accuracy를 구할 수 있다.
Sensitivity가 높다는 것은 False Negatives가 거의 없다는 것을 의미하며 Specificity가 높다는 것은 False Positivies가 거의 없다는 것을 의미한다.
Precision & Recall

Precision은 Positive라고 예측한 비율 중 진짜 Positive의 비율을 의미한다.
문서 검색을 예로 들어보면 Precision은 우리의 예측과 일치하는 문서와 전체 문서 사이의 비율이라고 할 수 있다.

Recall은 실제 Positive 데이터 중 Positive라고 예측한 비율을 의미한다.
문서 검색을 예로 들어보면 Recall은 우리의 예측과 일치하는 문서와 사용자가 예측한 총 문서 사이의 비율이라고 할 수 있다.
Precision의 기준은 모델이 예측한 것인 반면 Recall의 기준은 데이터이다.
F1 Score
Precision과 Recall은 모델 성능을 평가하는데 중요하므로 모두 사용되어야 한다. F1 score는 Precision과 Recall의 조화평균을 의미한다.

조화평균을 사용하는 이유는 평균이 Precision, Recall 중 작은 값에 가깝도록 하기 위함이다. 즉, 조화평균은 평균 계산에 사용된 값이 불균형 할수록 패널티가 부여되어 작은 값에 가깝도록 계산된다.
F1 score의 장점은 Precision이나 Recall이 매우 작다면 전체 스코어가 작아지게 된다. 두 Metrics 사이의 균형을 맞춰준다. 즉, Positive 클래스를 적은 샘플로 선택하는 경우 F1 score는 Positive, Negative 샘플 간 Metric의 균형을 조정하는데 도움을 줄 수 있다.

정리
모델 성능을 평가할 때 사용되는 평가지표들에 대해서 간단히 알아봤다.
Confusion Matrixs를 사용하여 우리는 맞음 여부와 예측 값의 조합을 TP, FN, FP, TN으로 나타낼 수 있었다.
Accuracy란 전체 대비 정확하게 예측한 개수의 비율을 의히했다. 즉, 전체 테스트 데이터의 개수를 정확하게 분류된 데이터의 개수로 나눈 것이다.
Sensitivity는 True Positive의 Rate를 구하는 것이며 Specificity는 True Negative의 비율을 구하는 것이다.
하지만 Accuracy는 Binary Classification에서 한계를 나타내므로 우리는 Precision, Recall을 사용하여 모델 성능을 평가했다.
Precision은 Positive라고 예측한 비율 중 진짜 Positive의 비율을 의미하며 Recall은 실제 Positive 중 Positive라고 예측한 비율을 의미한다.
Precision과 Recall 사이에는 Trade-off가 발생하지만 모델 성능을 평가하기 위해 모두 사용되어야한다. 따라서 우리는 F1 score라는 Precision과 Recall의 조화평균으로 모델 성능 평가지표로 사용하였다.

참고자료
https://github.com/gilbutITbook/080223
https://gaussian37.github.io/ml-concept-ml-evaluation/
https://www.linkedin.com/pulse/performance-metrics-evaluation-machine-learning-models-atanda/
https://dataconomy.com/2023/08/25/performance-metrics-in-machine-learning/
'머신러닝 & 딥러닝 > 머신러닝 기초' 카테고리의 다른 글
머신러닝 - Logistic Regression (0) 2024.03.04 머신러닝 - Linear Regression (2) 2024.02.08 머신러닝 - 지도학습, 비지도학습, 강화학습 (0) 2024.01.22 머신러닝 - Bias and Variance trade-off (0) 2024.01.09