-
[ICME 2024] Explicit Correlation Learning for Generalizable Cross-Modal Deepfake Detection딥러닝 논문 리뷰 2024. 11. 4. 17:02
초록
최근 다양한 종류의 Deepfake들이 나타나면서 이런 다양한 종류의 Deepfake들에 대해서 모델의 일반화 성능을 높이는 연구가 활발하게 진행되고있다.
이 논문은 교차 모달 상관관계를 학습하여 Deepfake 탐지 성능을 향상시키는 연구를 다룬다. 내용 정보를 기반으로 교차 모델 상관관계를 모델링하는 correlation distillation 기법을 사용해서 오디오와 영상 사이의 동기화에만 overfitting 되는 것을 방지한다. 또한 CMDFD(Cross Modal Deepfake Dataset)을 사용하여 다양한 형태의 Deepfake 데이터 셋을 대상으로 실험을 진행했다.
서론
기존 Deepfake는 얼굴 묘사, 얼굴 바꿔치기 등과 같이 개인적인 표정이나 정체성을 조작하는게 대부분이었다. 하지만 최근에는 talking-head generation, lip-sync 등과 같이 교차 모달 합성까지 Deepfakes가 발전했다. 예를 들어 특정 인물의 입모양과 머리 움직임을 특정 오디오 input과 동기화 시키는 등의 Deepfake가 나온거다. 이처럼 오디오 데이터만 가지고 특정 내용을 말하는거처럼 조작할 수 있기 때문에 보안에 큰 위협이 된다.
기존 Deepfake 탐지 모델은 특정 modality에는 좋은 성능을 보여줬지만 교차 모달에는 좋은 성능을 보여주지 못했다. 기존 교차 모달 탐지 방법은 out-of-sync나 오디오와 영상 간 불일치를 탐지하는 방법으로 가짜 데이터를 식별한다. 이런 모델들은 실제 영상과 비교해서 Deepfake video가 항상 오디오와 영상 사이에 불일치를 갖고 있다는 것을 전제로 한다. 하지만 이 가정이 모든 경우에 적용 되는 것이 아니다.

Talking head generation의 경우 실제 영상에 비해 낮은 오디오 영상 간 상관성이 낮게 나타나고있다. 이에 반해 Lip-sync generation의 경우 실제 영상에 비해 높은 오디오 영상 간 상관성을 나타내고있다. 이것은 오디오와 영상 간 동기화에만 의존하는 것이 다양한 종류의 교차 모달 deepfake를 식별하기 위한 신뢰성 있고 일반화된 방법이 아니라는 것이다. 따라서 이 연구에서는 오디오와 영상 간 불일치 편향을 분리하기 위해 Correlation Distillation 방법을 사용한다.
ASR(Audio Speech Recognition)과 VSR(Visual Speech Recognition)이 teacher model로 사용되며 오디오와 영상 간 음성 내용에 기반한 상관성에 소프트 라벨을 제공한다. 음성인식 모델이 영상이 가짜인지 진짜인지에 관계없이 내용 기반의 교차 모달 상관성을 제공할 수 있게된다. ASR과 VSR이 음성문자에 대해서 독립적으로 확률 분포를 생성하게 되며 서로 다른 modality에서 생성된 프레임별 특징들을 동일한 character set에 매핑한다. 이를 통해 시간 수준에서 교차 모달 상관성을 측정할 수 있게 되며 이 상관성이 소프트 라벨로 사용되어 오디오와 영상 간 동기화 품질을 평가하는 지표가 된다. 이 과정을 통해 이 연구에서는 내용 기반 관점에서 더 세밀한 동기화 상관성을 모델링하는 Framework를 만들어낸다.
기존 Deepfake 데이터셋은 얼마 안되는 교차 모달 위조 패턴만 갖고 있기 때문에 일반화 성능을 높이기 위해 이 연구에서는 CMDFD라는 데이터셋을 사용하였다. Lip-sync generation 방식 뿐만 아니라 더 다양한 Talking head generation 방식을 포함해서 Deepfake 탐지 범위를 넓혔다. 이 연구의 핵심은 아래와 같다.
- 내용 관점에서 교차 모델 상관성을 학습하여 더 다양한 교차 모달 deepfake를 식별할 수 있도록 설계했으며 오디오와 영상 간 동기화 여부에만 overfitting 되는 것을 방지했다.
- 기존 연구에서 Deepfake 데이터셋의 다양성을 보완하기 위해 Lip-sync, talking head generation을 포함해서 더 다양한 유형의 교차 모달 deepfake를 포함시킨 CMDFD라는 데이터셋을 활용했다.
연구 배경
1. 기존 Deepfake 생성 및 데이터셋
기존 Deepfake 기술들은 FaceForensics, DFDC와 같은 얼굴 정보에 조작에 대한 위조 방법에 초점이 맞춰져 있었다. 하지만 최근에는 Deepfakes 기술이 시각적 Deepfake 뿐만 아니라 음성복제나 음성 변환과 같은 기술로 생성된 오디오 deepfake나 교차 모달 deepfake를 포함하는 멀티 모달 형태로 진화했다. 교차 모달 deepfake란 특정 오디오 input에서 생성된 시각적인 위조를 뜻한다.
VideoReTalking, Audio2Head, MakeItTalk와 같은 방법은 머리 움직임과 입모양을 변조해서 만드는 deepfake인데 최근 이러한 방법들이 대두되고 있다. 이 연구에서는 이러한 위조 타입들을 데이터셋에 포함시켰다.
2. 기존 Deepfake 탐지
LipForensics는 학습된 lip-reading을 활용해서 입주변 왜곡된 패턴을 찾는 방법이며 FTCN은 일반적인 얼굴 위조 탐지를 위해 시간적 일관성을 학습하는 방법이다. 이러한 연구들은 다양한 유형의 시각적인 deepfake를 대응하는데 초점이 맞춰있다.
멀티 모달 영상 deepfake를 탐지하기 위해 오디오와 영상 간 특징을 융합하는 방법을 제시됐다. AVAD는 사전에 학습된 오디오와 영상 간 동기화 모델을 통해서 동기화 특징들을 예측하는 방법을 통해 교차 모달 deepfakes를 탐지한다. JointAV는 Deepfake 영상을 탐지하기 위해 오디오와 영상 쌍들의 동기화 패턴을 이용하는 방법이다. 그럼에도 불구하고 다른 형태의 교차 모달 deepfakes에 대해서 탐지기가 얼마나 일반화 될 수 있을지에 대한 연구가 여전히 필요하다.
연구 방법
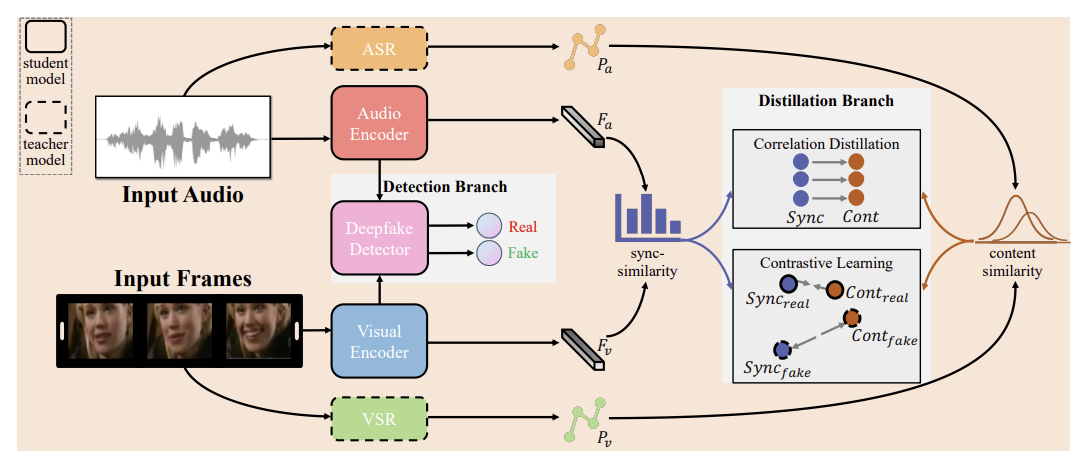
이 연구에서는 잠재적인 교차 모달 상관성을 모델링 하기 위해 2개의 브랜치를 사용하는 멀티 태스킹 framework를 소개한다.
1. Deepfake Detection Branch
주어진 영상에서 오디오를 MFCCs(Mel-Frequency Cepstral Coefficients)로 추출하고 시각 프레임에서 얼굴 부분을 탐지한다. 이렇게 추출된 특징들은 오디오와 비주얼 인코더에 입력되어 오디오 임베딩 Fa, 영상(시각) 임베딩 Fv가 생성된다. 그리고 이 임베딩들이 deepfake 탐지를 위해 탐지기에 입력된다. 탐지기는 2개의 cross attention 모듈을 갖고 있으며 Fa와 Fv는 각각의 모듈들을 위한 source sequence로 제공된다. 그 후 각각 모듈의 output들이 연결되 2진 탐지를 수행하기 위해 fully conntected layer에 입력된다. 이 브랜치의 loss function은 아래와 같으며 Si는 영상 예측 라벨을 뜻하고 Yi는 ground truth 라벨을 뜻한다.

2. Correlation Distillation Branch
이 브랜치는 교차 모달 상관성 증류를 위한 브랜치이다. 오디오와 영상 간 상관성을 추출하는 과정을 포함하며 Fa와 Fv의 각각 시간 프레임별로 cosine similarity를 계산하여 동기화 정도를 측정한다. 이 브랜치 학습에 제한을 두기 위해서 ASR과 VSR을 teacher 모델로 통합한다. 이 접근법의 근거는 ASR과 VSR이 음성내용에 대해서 독립적으로 확률분포를 생성한다는 것이다. 이 과정을 통해서 서로 다른 모달리티의 프레임별 특징들을 동일한 문자로 매핑할 수 있게 되며 모달리티 간 시간 수준에서 내용 상관성 측정이 가능해진다. 따라서 ASR과 VSR 예측 간의 Jansen-Shannon Divergence를 계산한다. 이는 오디오와 영상 간 상관성을 나타내긴 위한 소프트 수도 라벨을 할당하기 위함이며 이 라벨들은 오디오와 영상 모달리티 간 동기화 품질을 나타내는 지표 역할을 하게 된다.
이 브랜치는 아래와 같은 cross entropy기반 distillation loss function에 의해 최적화 되며 Pa는 ASR의 예측 확률, Pv는 VSR의 예측 확률을 나타낸다.

균일한 잠재 상관성을 모델링 하기 위해 joint-modal contrastive learning을 사용한다. 즉 두 모달리티를 직접적으로 대조를 적용하는 것 대신에 joint-modal 수준에 적용시킨다. 이는 내용과 동기화 정보에 대한 표현을 제한하기 위한 목적이다. 보통 Deepfake 생성 과정에서 오디오와 영상 프레임 간 유사도에 대해서 직접적인 제한을 가하는 loss function을 설계하지만 이렇게 되면 전체 영상에 시간적 정보와 의미적 정보의 일관성을 유지하지 못하는 경우가 많다. 따라서 실제 영상에서는 내용과 동기화 정보의 표현이 가짜 영상보다 본질적으로 서로 가깝다고 가정한다. 이러한 관점에서 이 연구에서는 실제 영상의 잠재 상관성 공간에서 내용과 동기화 표현간의 거리 가깝게 하고 가짜 영상에서는 이를 넓히는 contrastive loss function을 사용하였다.

- Cont : JS Divergence로 측정된 내용 상관성
- Sync : correlation distillation branch에서 얻은 동기화 유사성
- di : 유클리드 거리
- margin : hyper parameter

- N : 학습 영상의 수
- T : 영상 프레임의 시간적 차원
- correlation distillation, contrastive learning이 매 프레임마다 수행되며 세밀한 동기화 및 내용 상관성을 추출한다.
교차 모달 딥페이크 데이터셋
현재 Deepfake 데이터셋은 시각적 위조가 대부분이다. 따라서 이는 교차 모달 생성 방법에 적합하지 않다. 이 연구에서는 CMDFD라는 데이터셋을 사용하면 이는 lip-sync generation과 talking head generation 위조를 포함하는 더 많은 교차 모달 위조 방법을 포함한다. 우선 VoxCeleb2에서 실제 영상을 수집하고 명확한 음성이 있는 1000개의 identity를 선정한다. 각 identity는 4가지 위조 방법으로 조작된다.
- Lip-syncing 모델
- Wav2Lip : 어느 특정 말이나 언어에 적용될 수 있는 lip-sync 영상
- VideoReTalking : 사진 같은 표현으로 잘 알려진 최신 lip-sync 생성 방법
- Talking head generation
- Audio2Head : 자연스로운 머리 움직임 생성
- MakeltTalk : 말하는 사람의 talking head generation을 위해 얼굴 주변 뿐만 아니라 입술까지 조작하는 기술
이 연구에서는 특정 사람의 시각적 자료를 조작하기 위해 해당 인물의 음성과 과 다른 사람의 음성을 사용하여 실험한다. 이는 한 사람의 음성을 사용하여 시각 자료를 조작하는 일반적인 상황을 재현하기 위함이다.
실험
1. Setting
1-1. Implementations
- Audio 인코더 : 2D ResNet34 network
- Visual 인코더 : Visual Frontend와 시각적 시간 network 포함
- 초기 Learning Rate
- 10 to the power of negative 4
- Epoch 마다 5%씩 감소
- Audio 트랙 : 16kHz로 리샘플링
- Video : 25 fps로 설정
- 얼굴 이미지 : 112 x 112 사이즈
- Fa, Fv feature dimension : 128
- L(contra) margin : 1.0
- Teacher model : 공개된 음성 인식 모델
1-2. Datasets
- CMDFD
- FakeAVCeleb(FAV) : 다수의 위조 타입을 포함한 Audio-Visual 데이터셋
- Wav2Lip : FaceSwap을 통해 생성된 Audio, Visual deepfake(교차 모달 위조)
- FaceGAN
- 2개 평가 protocol
- 탐지기의 일반화 성능을 입증하기 위함
- 데이터셋 내부와 데이터셋 간 일반화
- AVAD(첫번째 protocol) : FAV 데이터셋에서 unseen 조작 유형 탐지를 평가하기 위함
- FAV의 생성 methods와 위조 모달리티에 기반한 5개의 leave-one-out 일반화 테스트로 수행됨
- RVFA, RVRA_W2L, FVFA_FS, FVFA_GAN, FVFA_W2L
- 접두사 : 위조 모달리티를 뜻함 (ex. RVFA = Real Video Fake Audio)
- 접미사 : 위조 method의 축약어 (Wav2Lip, FaceSwap)
- 두번째 protocol : 탐지기는 전체 FAV 데이터셋으로 학습하고 CMDFD 데이터셋으로 각각의 위조 타입을 테스트함.
- 다양한 교차 모달 위조 타입에 대해서 일반화 성능을 평가하기 위함
2. Detection Generalization Comparision
우선 5개의 평가 protocol을 기준으로 기존 Deepfake 탐지기와 비교하였다.

위 표에서 알 수 있듯이 해당 연구가 98.8 가장 높은 AUC 점수로 visual 위조 뿐만 아니라 거의 모든 위조 타입에서 가장 좋은 성능을 입증하였다. 특히 오디오 deepfake에서 높은 일반화 성능을 나타냈으며 unimodal 뿐만 아니라 교차 모달 deepfake 탐지에서도 높은 성능을 나타냈다. 단일 모달리티만 위조 됐을때도 의심스로운 교차 모달 아티팩트가 남아있기 때문에 다양한 유형의 위조를 탐지하기 위해서 내재된 교차 모델 패턴을 모델링 하는 것이 중요하다.

교차 모달 단서를 탐지하는데 특화된 2개의 오픈소스 모델을 재현해서 2번째 평가 protocol 하에 이 논문 연구와 비교하였다. 위 표는 해당 내용을 나타낸다.
- _S : 말하는 사람의 음성을 쓴 생성 타입
W2L 위조에 대해 AVAD, JointAV, 해당 연구 모델 모두 높은 성능을 나타낸다(FAV 트레이닝 세트에서 학습 된 위조 유형). AVAD, JointAV 모두 CMDFD에 비해서 AUC 점수가 낮음을 통해서 새로운 위조 타입을 진짜로 분류하는 경향이 있음을 확인할 수 있다. 두 방법 모두 Deepfake 영상을 식별하기 위해서 오디오와 영상 간 동기화에만 의존하기 때문이다.
해당 논문의 연구 방법은 오디오와 영상 간의 일관된 상관성을 학습하면서 오디오와 영상 간 동기화 패턴에 overfitting되는 것을 방지한다. 해당 연구는 모든 유형의 위조에 대해서 높은 일반화 성능을 보장하고 있다. 거의 모든 방법들이 특정 대상의 음성을 사용하여 생성된 위조에 대해서 낮은 성능을 보인다. 이것이 의미하는 바는 오디오와 영상 간 요소가 일치하는 Deepfake 탐지가 더 어렵다는 것을 의미하므로 여전히 이 경우에 대해서 연구가 필요하다.
3. Ablation Study

- w/o Cons&Dis : 인코더와 디코더를 기반으로 한 Detection Branch만 갖고 있는 단순한 모델
- w/o Cons : Contrastive learning 없이 Detection Branch와 Correlation Branch로 구성 되어 있는 multi task framework
위 표에서 알 수 있듯이 해당 논문의 연구 방법이 2가지의 방법과 비교해서 성능이 우수함을 확인할 수 있다.
결론
오디오와 영상 간 Correlation Distillation Branch를 Detection 파이프라인에 통합함으로써 내용 수준에서 세밀한 동기화 상관성을 효과적으로 탐지 할 수 있었다. 즉, 일반화 성능 향상을 위해 다양한 위조 유형에 걸쳐 균일화 된 교차 모달 상관성을 학습하는 것이 중요하다는 것을 알 수 있다.